

Though the term Web Scraping looks very techy, it is just an extraction of the content of any website. This tutorial is will help you to learn web scraping using Node JS and Express JS in the Google Cloud server. To scrap the data from any website, we first need to build a Node JS app.
If you have not read my blog on How to build a Node JS and Express JS app, you can go through it first, which is the prerequisite of this tutorial.
I hope now you know how to build an API. Let us move further and learn web scraping using Node JS. In this tutorial, we would be scraping the latest news from an online news portal Firstpost.
There are many NPM packages available for web scraping using Node JS, but I prefer to use Cheerio and Axios as they make the code fast, easy, and readable.
As you have learned to build an API in Google Cloud and ran it successfully, you should also know how to stop the app running. You must be seeing the below lines in the terminal when your app is running. Press "CTRL + C" to stop the app running.
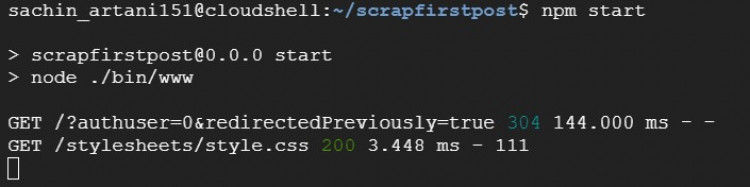
To reflect any changes in the app, we first have to restart the app by stoping it with "CTRL + C" and starting it by running the command - npm start.
Beginning Web Scraping Using Node JS
Now that you have stopped the app, you have to install Cheerio and Axios in the app. Run the below command to install both at the same time.
npm i cheerio axiosNow that the packages are installed, open the file routes/index.js and import Cheerio and Axios class in the file at the top of it.
const cheerio = require('cheerio');
const axios = require('axios');We have seen in the tutorial build a Node JS and Express JS app, that all the processing code is written in the get function definition. Inside the get function, we will first declare the URL to be scrapped.
const url = 'https://www.firstpost.com/';Now to send a request to the above URL we will call the Get function of Axios.
axios.get(url).then((resp) => {
// Code to scrap data
}By this time, we have scraped entire HTML data of the called URL into local variable resp which is accessible inside Axios. You can check the response by writing console.log(resp); inside Axios and run the app through the terminal. The output will be printed in the terminal.
To store the scraped data and return it to the caller, we will declare a local scoped array inside the Axios Get function.
var result = [];Load all the HTML data received from the URL into Cheerio, so that we can traverse through the DOM object at ease and scrap the required data.
var $ = cheerio.load(resp.data);Now that the Cheerio function is loaded in $, we are ready to collect values from the website. Open the Firstpost website and open Developer Tools in your browser. You could see that all of the latest posts are enclosed in a div tag with class big-thumb.
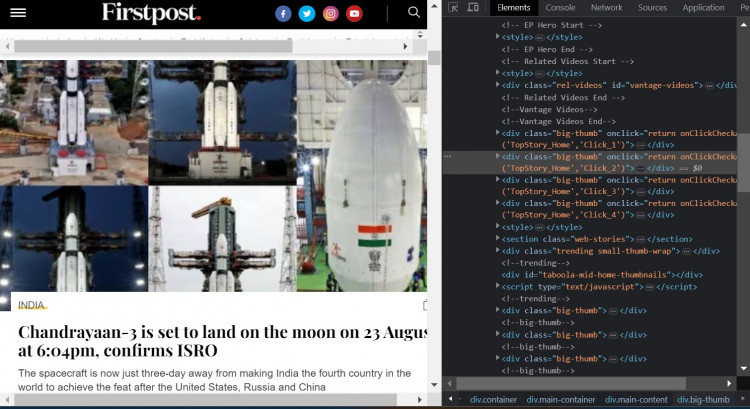
This means we have to scrap the post details from each of these divisions and append them into the array result.
We would be scraping four fields value for each post which are Post Title, Post URL, Post Image, and Post Excerpt.
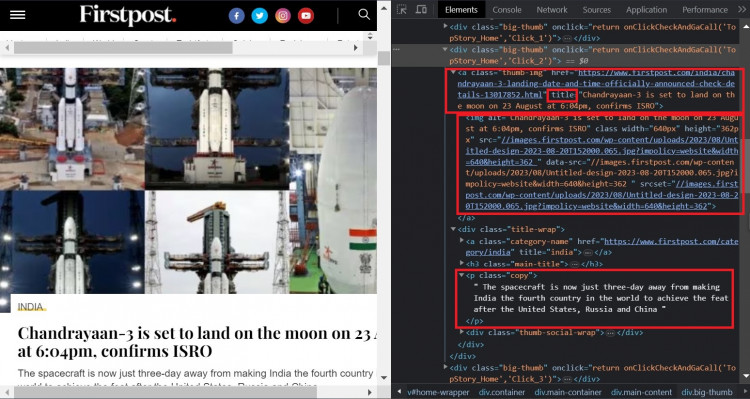
If you look at the hierarchy of elements in the picture above, you will see the division with class big-thumb is the repetitive section for each of the blog post which has -
- Post URL - In the anchor tag of class thumb-img
- Post Image URL - Attribute (data-src) of the img tag which is children of the anchor (a) tag of class thumb-img
- Post Title - Text value of the anchor (a) tag which is the parent of H3 heading tag with class main-title and H3 tag is also the children of the division with class title-wrap
- Post Excerpt - Text value of the Paragraph (p) tag of class copy which is the children of the division with the class title-wrap
as children of it.
Hence, to scrap all of these values for each of the blog post, we would be running a loop and scrap data for each of the DOM nodes individually and append all values together in a row in our final array result. To achieve this, add the below code.
$('.main-content > .big-thumb').each( (index,element) => {
var title = $(element).children('.title-wrap')
.children('.main-title').children('a').text();
if(title)
title = title.replace(/\n/g,'').trim();
var url = $(element).children('a').attr('href');
var image = $(element).children('a').children('img')
.attr('data-src');
if(image)
image = "https:" + image;
var excerpt = $(element).children('.title-wrap')
.children('.copy').text();
if(excerpt)
excerpt = excerpt.replace(/\n/g,'').trim();
result.push({title,image,url,excerpt});
});In the above code section, we are running a loop at each division with class big-thumb who are direct children of the division with class .main-content.
Inside the loop, $(element) will be treated as a DOM node which is actually a div tag with class big-thumb. So, we are scraping required fields by considering $(element) as the parent of all.
As the scraped text string contains "\n" and leading and trailing spaces, hence we trimmed it and re-assigned.
At the end, we pushed all of the details for each post into an array result.
Now that we have scrapped all required data, we are good to send it back to the caller. Add below line outside Axios call.
res.send(result);That's it. We have learned web scraping using Node JS and build an API which scraps all the latest blog posts from the website of Firstpost. To test it, run the below command in terminal and run the app in port which is maintained in the file bin/www.
npm startYou can refer last tutorial for the errors that may come which running the app.
Below is the code with error handling that should be kept in index.js file in the folder routes.
const express = require('express');
const cheerio = require('cheerio');
const axios = require('axios');
const router = express.Router();
router.get('/', function(req, res, next) {
const url = 'https://www.firstpost.com/';
axios.get(url).then((resp) => {
var result = [];
var $ = cheerio.load(resp.data);
console.log(typeof($));
$('.main-content > .big-thumb').each( (index,element) => {
var title = $(element).children('.title-wrap').children('.main-title').children('a').text();
if(title)
title = title.replace(/\n/g,'').trim();
var url = $(element).children('a').attr('href');
var image = $(element).children('a').children('img').attr('data-src');
if(image)
image = "https:" + image;
var excerpt = $(element).children('.title-wrap').children('.copy').text();
if(excerpt)
excerpt = excerpt.replace(/\n/g,'').trim();
result.push({title,image,url,excerpt});
});
res.send(result);
}).catch((err) => {
console.log(err);
res.send([]);
});
});
module.exports = router;Above code will catch the exception coming while scraping the data from website and print in the terminal and give blank response to avoid any runtime error. You can check the error in console and try to resolve it.
If you get yourself stuck in the middle of process of Web Scraping, feel free to shoot questions in the comments.
Thanks for learning Web Scraping using Node Js and Express JS!





